https://docs.voxel51.com/tutorials/yolov8.html
Fine-tune YOLOv8 models for custom use cases with the help of FiftyOne — FiftyOne 0.21.4 documentation
Fine-tune YOLOv8 models for custom use cases with the help of FiftyOne Since its initial release back in 2015, the You Only Look Once (YOLO) family of computer vision models has been one of the most popular in the field. In late 2022, Ultralytics announced
docs.voxel51.com
YOLOv8에 커스텀 데이터를 적용해서 객체 탐지 모델을 만들어야 한다. 위 튜토리얼을 참고로 작업을 진행해본다.
1. 기본 셋업
우선 fiftyone과 ultralycis를 설치해준다.
pip install fiftyone ultralytics
그리고
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
import numpy as np
import os
from tqdm import tqdm
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")
seg_model = YOLO("yolov8n-seg.pt")
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
def export_yolo_data(
samples,
export_dir,
classes,
label_field = "ground_truth",
split = None
):
if type(split) == list:
splits = split
for split in splits:
export_yolo_data(
samples,
export_dir,
classes,
label_field,
split
)
else:
if split is None:
split_view = samples
split = "val"
else:
split_view = samples.match_tags(split)
split_view.export(
export_dir=export_dir,
dataset_type=fo.types.YOLOv5Dataset,
label_field=label_field,
classes=classes,
split=split
)
coco_val_dir = "coco_val"
export_yolo_data(dataset, coco_val_dir, coco_classes)요거까지 해주면 coco dataset의 세팅까지 끝난다. 돌리는데 시간이 꽤 오래 걸린다. coco dataset 다운로드 하고 annotation 추출하고, validation set 만드는 작업까지 한번에 해준다.
다음으로
yolo task=detect mode=predict model=yolov8n.pt source=coco_val/images/val save_txt=True save_conf=Trueyolo를 돌려주면 validation set 이미지들에 대해서

객체 탐지를 하게 된다.
결과는

이런식으로 나온다.
2. Load YOLOv8 predictions in FiftyOne
다음 작업은 이 결과를 fiftyone에서 읽는 것
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
import numpy as np
import os
from tqdm import tqdm
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")
seg_model = YOLO("yolov8n-seg.pt")
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
coco_classes = [c for c in dataset.default_classes if not c.isnumeric()]
coco_val_dir = "coco_val"
def read_yolo_detections_file(filepath):
detections = []
if not os.path.exists(filepath):
return np.array([])
with open(filepath) as f:
lines = [line.rstrip('\n').split(' ') for line in f]
for line in lines:
detection = [float(l) for l in line]
detections.append(detection)
return np.array(detections)
def _uncenter_boxes(boxes):
'''convert from center coords to corner coords'''
boxes[:, 0] -= boxes[:, 2]/2.
boxes[:, 1] -= boxes[:, 3]/2.
def _get_class_labels(predicted_classes, class_list):
labels = (predicted_classes).astype(int)
labels = [class_list[l] for l in labels]
return labels
def convert_yolo_detections_to_fiftyone(
yolo_detections,
class_list
):
detections = []
if yolo_detections.size == 0:
return fo.Detections(detections=detections)
boxes = yolo_detections[:, 1:-1]
_uncenter_boxes(boxes)
confs = yolo_detections[:, -1]
labels = _get_class_labels(yolo_detections[:, 0], class_list)
for label, conf, box in zip(labels, confs, boxes):
detections.append(
fo.Detection(
label=label,
bounding_box=box.tolist(),
confidence=conf
)
)
return fo.Detections(detections=detections)
def get_prediction_filepath(filepath, run_number = 1):
run_num_string = ""
if run_number != 1:
run_num_string = str(run_number)
filename = filepath.split("/")[-1].split(".")[0]
return f"runs/detect/predict{run_num_string}/labels/{filename}.txt"
def add_yolo_detections(
samples,
prediction_field,
prediction_filepath,
class_list
):
prediction_filepaths = samples.values(prediction_filepath)
yolo_detections = [read_yolo_detections_file(pf) for pf in prediction_filepaths]
detections = [convert_yolo_detections_to_fiftyone(yd, class_list) for yd in yolo_detections]
samples.set_values(prediction_field, detections)
filepaths = dataset.values("filepath")
prediction_filepaths = [get_prediction_filepath(fp) for fp in filepaths]
dataset.set_values(
"yolov8n_det_filepath",
prediction_filepaths
)
add_yolo_detections(
dataset,
"yolov8n",
"yolov8n_det_filepath",
coco_classes
)
session = fo.launch_app(dataset)
input("EnterKey to exit fiftyone")위 코드를 실행하면 된다.
그런데, Labels가 제대로 나오질 않는다. 문제는 filepath가 이상하게 잡혀있다..
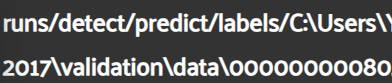
yolov8n 의 패스 폴더가 이렇게 잡힌다는 것...
def get_prediction_filepath(filepath, run_number = 1):
run_num_string = ""
if run_number != 1:
run_num_string = str(run_number)
filename = filepath.split("/")[-1].split(".")[0]
filename = filename.replace("C:\\Users\\YbKim\\fiftyone\\coco-2017\\validation\\data\\","")
return f"runs/detect/predict{run_num_string}/labels/{filename}.txt"그래서 get_prediction_filepath를 강제로 위와 같이 수정했다. 필요한 경우 다른 형태로 쓰길....
결과적으로

GT와 yolov8n 을 적용한 detection 결과물을 확인할 수 있었다.
다음 단계로 넘어가보자.
원문에서는 segmentation mask도 같이 draw하게 햇는데, 이부분은 뭔가 더 조사해야 할거 같아서
3. Evaluate YOLOv8 model predictions
로 넘어가본다.
mAP = detection_results.mAP()
print(f"mAP = {mAP}")
counts = dataset.count_values("ground_truth.detections.label")
top20_classes = sorted(
counts,
key=counts.get,
reverse=True
)[:20]
detection_results.print_report(classes=top20_classes)
위 코드를 추가하고 실행을 해보니
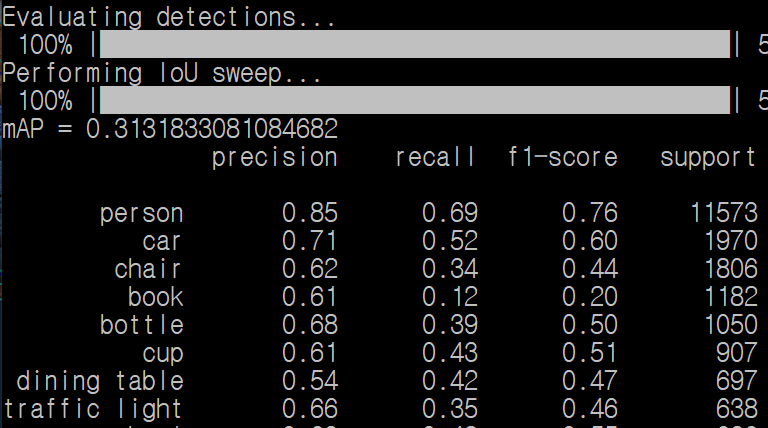
이런 결과가 나왔다.
자 이제 파인튜닝의 레벨로 넘어가보자.
4. Curate data for fine-tuning
bird 만으로 구성된 테스트 셋을 만들어준다.
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
import numpy as np
import os
from tqdm import tqdm
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")
seg_model = YOLO("yolov8n-seg.pt")
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
coco_classes = [c for c in dataset.default_classes if not c.isnumeric()]
coco_val_dir = "coco_val"
def read_yolo_detections_file(filepath):
detections = []
if not os.path.exists(filepath):
return np.array([])
with open(filepath) as f:
lines = [line.rstrip('\n').split(' ') for line in f]
for line in lines:
detection = [float(l) for l in line]
detections.append(detection)
return np.array(detections)
def _uncenter_boxes(boxes):
'''convert from center coords to corner coords'''
boxes[:, 0] -= boxes[:, 2]/2.
boxes[:, 1] -= boxes[:, 3]/2.
def _get_class_labels(predicted_classes, class_list):
labels = (predicted_classes).astype(int)
labels = [class_list[l] for l in labels]
return labels
def convert_yolo_detections_to_fiftyone(
yolo_detections,
class_list
):
detections = []
if yolo_detections.size == 0:
return fo.Detections(detections=detections)
boxes = yolo_detections[:, 1:-1]
_uncenter_boxes(boxes)
confs = yolo_detections[:, -1]
labels = _get_class_labels(yolo_detections[:, 0], class_list)
for label, conf, box in zip(labels, confs, boxes):
detections.append(
fo.Detection(
label=label,
bounding_box=box.tolist(),
confidence=conf
)
)
return fo.Detections(detections=detections)
def get_prediction_filepath(filepath, run_number = 1):
run_num_string = ""
if run_number != 1:
run_num_string = str(run_number)
filename = filepath.split("/")[-1].split(".")[0]
filename = filename.replace("C:\\Users\\YbKim\\fiftyone\\coco-2017\\validation\\data\\","")
return f"runs/detect/predict{run_num_string}/labels/{filename}.txt"
def add_yolo_detections(
samples,
prediction_field,
prediction_filepath,
class_list
):
prediction_filepaths = samples.values(prediction_filepath)
yolo_detections = [read_yolo_detections_file(pf) for pf in prediction_filepaths]
detections = [convert_yolo_detections_to_fiftyone(yd, class_list) for yd in yolo_detections]
samples.set_values(prediction_field, detections)
def convert_yolo_segmentations_to_fiftyone(
yolo_segmentations,
class_list
):
detections = []
boxes = yolo_segmentations.boxes.xywhn
if not boxes.shape or yolo_segmentations.masks is None:
return fo.Detections(detections=detections)
_uncenter_boxes(boxes)
masks = yolo_segmentations.masks.masks
labels = _get_class_labels(yolo_segmentations.boxes.cls, class_list)
for label, box, mask in zip(labels, boxes, masks):
## convert to absolute indices to index mask
w, h = mask.shape
tmp = np.copy(box)
tmp[2] += tmp[0]
tmp[3] += tmp[1]
tmp[0] *= h
tmp[2] *= h
tmp[1] *= w
tmp[3] *= w
tmp = [int(b) for b in tmp]
y0, x0, y1, x1 = tmp
sub_mask = mask[x0:x1, y0:y1]
detections.append(
fo.Detection(
label=label,
bounding_box = list(box),
mask = sub_mask.astype(bool)
)
)
return fo.Detections(detections=detections)
filepaths = dataset.values("filepath")
prediction_filepaths = [get_prediction_filepath(fp) for fp in filepaths]
dataset.set_values(
"yolov8n_det_filepath",
prediction_filepaths
)
add_yolo_detections(
dataset,
"yolov8n",
"yolov8n_det_filepath",
coco_classes
)
test_dataset = dataset.filter_labels(
"ground_truth",
F("label") == "bird"
).filter_labels(
"yolov8n",
F("label") == "bird",
only_matches=False
).clone()
test_dataset.name = "birdsDataset"
test_dataset.persistent = True
## set classes to just include birds
classes = ["bird"]
session = fo.launch_app(test_dataset)
input("EnterKey to exit fiftyone")test_dataset.name 부분을 약간 수정했다.
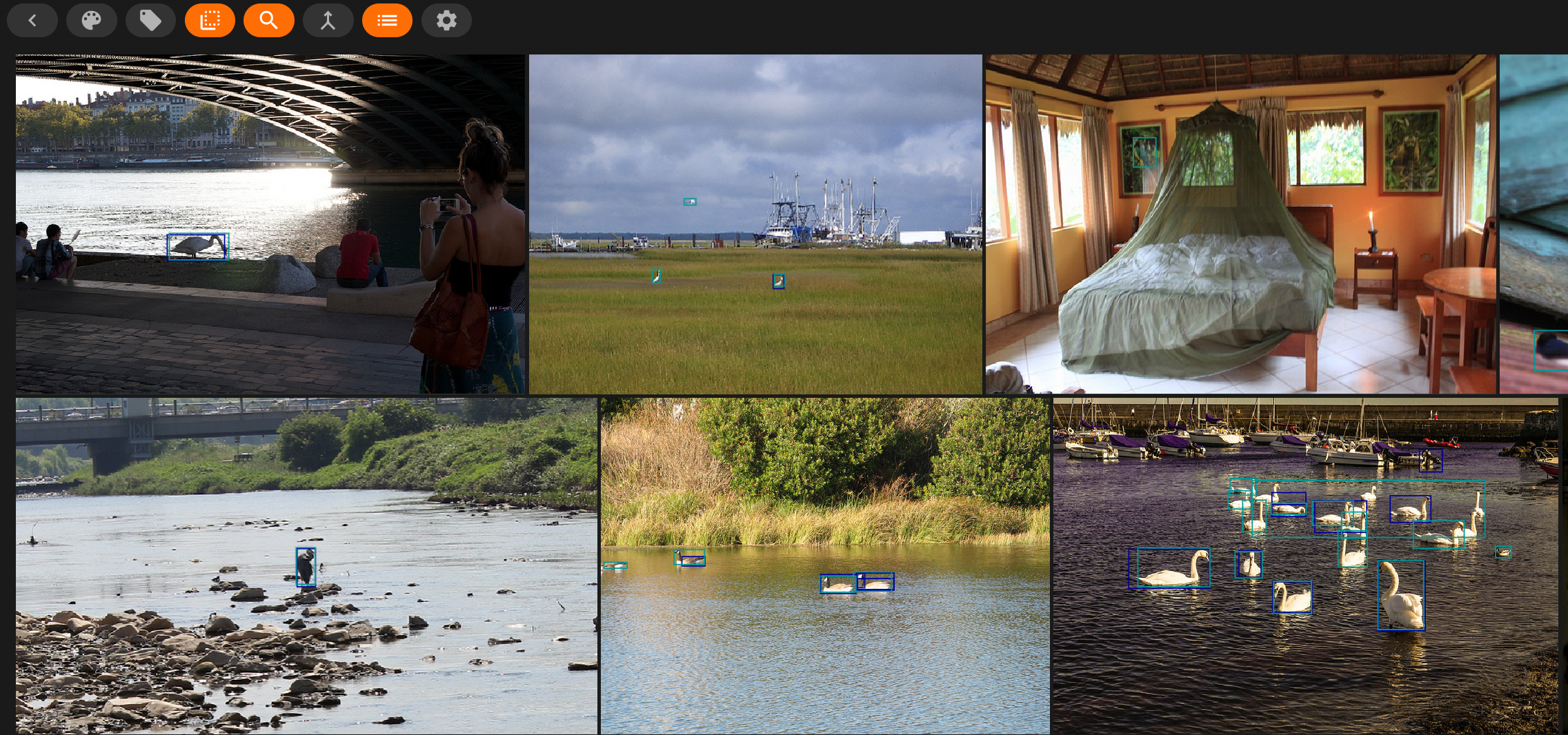
실행 결과는 위와 같다.
5. Generate training set
이제 트레이닝 데이터를 만들자. 추가 데이터는 구글의 Open Images dataset을 통해서 가져오는 형태다. 원문에서는 val과 training을 나누고 섞는 과정은 다음 단계에서 했는데, 나는 이 단계에서 한꺼번에 해주기로 했다.
train_dataset = foz.load_zoo_dataset(
'coco-2017',
split='train',
classes=["bird"],
).clone()
train_dataset.name = "trainBirds"
train_dataset.persistent = True
train_dataset.save()
oi_samples = foz.load_zoo_dataset(
"open-images-v6",
classes = ["Bird"],
only_matching=True,
label_types="detections"
).map_labels(
"ground_truth",
{"Bird":"bird"}
)
train_dataset.merge_samples(oi_samples)
train_dataset.untag_samples(train_dataset.distinct("tags"))
## split into train and val
four.random_split(
train_dataset,
{"train": 0.8, "val": 0.2}
)
## export in YOLO format
export_yolo_data(
train_dataset,
"trainBirds",
classes,
split = ["train", "val"]
)위 코드를 실행하면 아래 처럼 나온다.
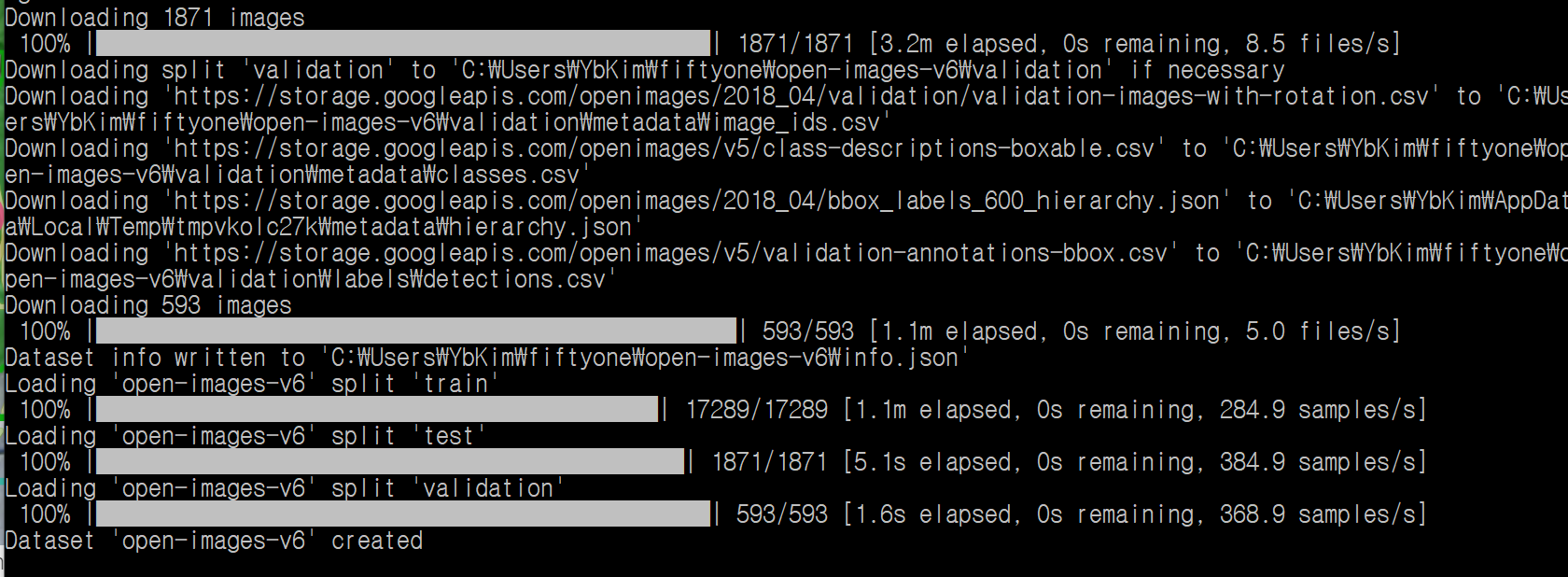
6. Fine-tune a YOLOv8 detection model
를 실행해주자.
그러면
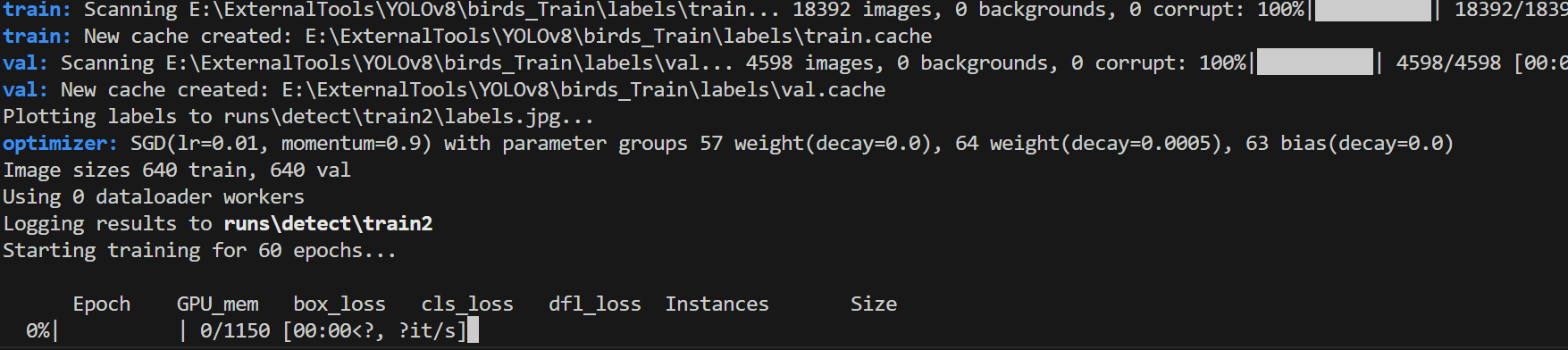
이런식으로 뭔가 진행이 된다. 화면에서도 보이지만 1 epoch당 2시간 정도 소요된다. CPU 버전인 경우...
GPU를 이용해야 겠다.
yolo task=detect mode=train model=yolov8n.pt data=birds_train/dataset.yaml epochs=60 imgsz=640 batch=16 device=0
이라고 명령하면 gpu를 쓴다. (pytorch가 gpu를 지원하는 버전으로 설치되어있어야 한다)
그러면 1 epoch를 도는데, 4분 정도 소요된다. (2080ti 기준)

실험 결과는 모든 작업이 끝난 뒤에 확인해보도록 하자.
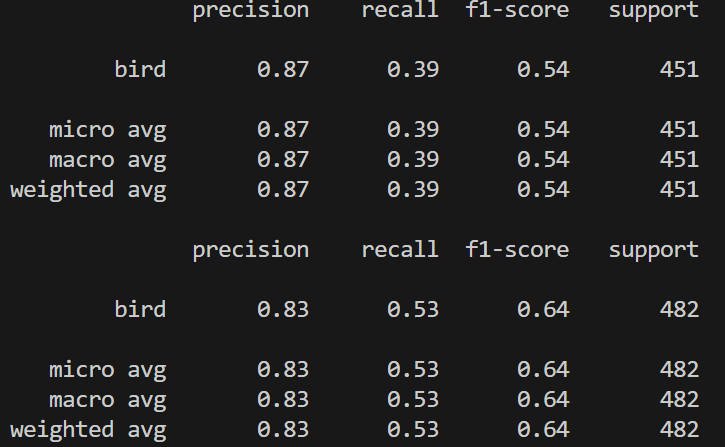
fiftyone 튜토리얼에 있던것과 같은 결과가 나왔다.
휴 힘들었다.....
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
import numpy as np
import os
from tqdm import tqdm
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")
seg_model = YOLO("yolov8n-seg.pt")
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
coco_classes = [c for c in dataset.default_classes if not c.isnumeric()]
coco_val_dir = "coco_val"
def read_yolo_detections_file(filepath):
detections = []
if not os.path.exists(filepath):
return np.array([])
with open(filepath) as f:
lines = [line.rstrip('\n').split(' ') for line in f]
for line in lines:
detection = [float(l) for l in line]
detections.append(detection)
return np.array(detections)
def _uncenter_boxes(boxes):
'''convert from center coords to corner coords'''
boxes[:, 0] -= boxes[:, 2]/2.
boxes[:, 1] -= boxes[:, 3]/2.
def _get_class_labels(predicted_classes, class_list):
labels = (predicted_classes).astype(int)
labels = [class_list[l] for l in labels]
return labels
def convert_yolo_detections_to_fiftyone(
yolo_detections,
class_list
):
detections = []
if yolo_detections.size == 0:
return fo.Detections(detections=detections)
boxes = yolo_detections[:, 1:-1]
_uncenter_boxes(boxes)
confs = yolo_detections[:, -1]
labels = _get_class_labels(yolo_detections[:, 0], class_list)
for label, conf, box in zip(labels, confs, boxes):
detections.append(
fo.Detection(
label=label,
bounding_box=box.tolist(),
confidence=conf
)
)
return fo.Detections(detections=detections)
def get_prediction_filepath(filepath, run_number = 1):
run_num_string = ""
if run_number != 1:
run_num_string = str(run_number)
filename = filepath.split("/")[-1].split(".")[0]
filename = filename.replace("C:\\Users\\YbKim\\fiftyone\\coco-2017\\validation\\data\\","")
return f"runs/detect/predict{run_num_string}/labels/{filename}.txt"
def add_yolo_detections(
samples,
prediction_field,
prediction_filepath,
class_list
):
prediction_filepaths = samples.values(prediction_filepath)
yolo_detections = [read_yolo_detections_file(pf) for pf in prediction_filepaths]
detections = [convert_yolo_detections_to_fiftyone(yd, class_list) for yd in yolo_detections]
samples.set_values(prediction_field, detections)
def convert_yolo_segmentations_to_fiftyone(
yolo_segmentations,
class_list
):
detections = []
boxes = yolo_segmentations.boxes.xywhn
if not boxes.shape or yolo_segmentations.masks is None:
return fo.Detections(detections=detections)
_uncenter_boxes(boxes)
masks = yolo_segmentations.masks.masks
labels = _get_class_labels(yolo_segmentations.boxes.cls, class_list)
for label, box, mask in zip(labels, boxes, masks):
## convert to absolute indices to index mask
w, h = mask.shape
tmp = np.copy(box)
tmp[2] += tmp[0]
tmp[3] += tmp[1]
tmp[0] *= h
tmp[2] *= h
tmp[1] *= w
tmp[3] *= w
tmp = [int(b) for b in tmp]
y0, x0, y1, x1 = tmp
sub_mask = mask[x0:x1, y0:y1]
detections.append(
fo.Detection(
label=label,
bounding_box = list(box),
mask = sub_mask.astype(bool)
)
)
return fo.Detections(detections=detections)
def export_yolo_data(
samples,
export_dir,
classes,
label_field = "ground_truth",
split = None
):
if type(split) == list:
splits = split
for split in splits:
export_yolo_data(
samples,
export_dir,
classes,
label_field,
split
)
else:
if split is None:
split_view = samples
split = "val"
else:
split_view = samples.match_tags(split)
split_view.export(
export_dir=export_dir,
dataset_type=fo.types.YOLOv5Dataset,
label_field=label_field,
classes=classes,
split=split
)
filepaths = dataset.values("filepath")
prediction_filepaths = [get_prediction_filepath(fp) for fp in filepaths]
dataset.set_values(
"yolov8n_det_filepath",
prediction_filepaths
)
add_yolo_detections(
dataset,
"yolov8n",
"yolov8n_det_filepath",
coco_classes
)
test_dataset = dataset.filter_labels(
"ground_truth",
F("label") == "bird"
).filter_labels(
"yolov8n",
F("label") == "bird",
only_matches=False
).clone()
#test_dataset.persistent = True
## set classes to just include birds
classes = ["bird"]
##new detector data
filepaths = test_dataset.values("filepath")
prediction_filepaths = [get_prediction_filepath(fp, run_number=3) for fp in filepaths]
print(prediction_filepaths)
test_dataset.set_values(
"yolov8n_bird_det_filepath",
prediction_filepaths
)
add_yolo_detections(
test_dataset,
"yolov8n_bird",
"yolov8n_bird_det_filepath",
classes
)
base_bird_results = test_dataset.evaluate_detections(
"yolov8n",
eval_key="base",
compute_mAP=True,
)
finetune_bird_results = test_dataset.evaluate_detections(
"yolov8n_bird",
eval_key="finetune",
compute_mAP=True,
)
print("yolov8n mAP: {}.format(base_bird_results.mAP())")
print("fine-tuned mAP: {}.format(finetune_bird_results.mAP())")
base_bird_results.print_report(classes=classes)
finetune_bird_results.print_report(classes=classes)
export_yolo_data(
test_dataset,
"birds_combined_230719",
classes
)
session = fo.launch_app(test_dataset)
input("EnterKey to exit fiftyone")위는 확인을 위해서 썼던 코드다.
코드를 제대로 이해를 하지 못하고 코딩을 하니 이리저리 시간만 보내버렸네 ㅠㅠ
이제 커스텀 데이터를 가지고 더 작업해봐야겠다...
'인공지능 공부' 카테고리의 다른 글
| Generating Custom data for object detection with Labelme (1) | 2023.07.19 |
|---|---|
| Setting VS Code with Anaconda in Windows (0) | 2023.07.18 |
| ChoreoMaster: Choreography-Oriented Music-Driven Dance Synthesis 읽어보기 (0) | 2023.07.13 |
| EISeg running guide [win10] (0) | 2023.07.13 |
| PaddleSeg Running guide (0) | 2023.07.11 |


