OpenManus 설치 및 활용 후기를 써본다
https://github.com/mannaandpoem/OpenManus/blob/main/README_ko.md
OpenManus/README_ko.md at main · mannaandpoem/OpenManus
No fortress, purely open ground. OpenManus is Coming. - mannaandpoem/OpenManus
github.com
위 링크의 내용을 쭉 따라 해본 것인데,

이 과정이 잘 안될 수 있다. 그런데 그냥 탐색기로 해당 폴더에 들어가서

이렇게 복사만 해주면 된다.
다음으로는

이 과정을 해야 하는데, 이게 무슨말인지 잘 이해가 안된다.....
알고보니 MANUS 자체는 그냥 LLM을 엮어서 기능을 만들어주는 하나의 에이전트의 역할을 하는 것이고, 그 내부에 다양한 LLM모델을 쓸 수 있는 것으로 보인다.
그래서 gpt건 소넷이건, 딥시크건 api 형태로 이용 가능한 LLM 서비스를 명시해야 하는 것....
대부분 API 형태로 이용하면 토큰당 비용을 내는 것으로 보인다.
그럼 로컬로 구축할 수 있는 LLM은 뭐가 있는지 알아봐야겠다 .
https://talesoff.tistory.com/182
OLLAMA로 로컬 API 서버 돌려보기
로컬 LLM 서버를 돌려보려고 이리저리 뒤져보다가, 올라마를 쓰면 생각보다 쉽게 구동이 가능하다는 것을 확인했다. 바로 PC 세팅해주고, 설치를 해보았다. 작동도 매우 간단하더라. 그냥 올라
talesoff.tistory.com
방법을 알아내서 서버 구축 완료!
# Global LLM configuration
[llm]
model = "deepseek-r1:70b"
base_url = "http://192.168.1.177:11434/api/generate"
api_key = ""
max_tokens = 4096
temperature = 5.0
# [llm] #AZURE OPENAI:
# api_type= 'azure'
# model = "YOUR_MODEL_NAME" #"gpt-4o-mini"
# base_url = "{YOUR_AZURE_ENDPOINT.rstrip('/')}/openai/deployments/{AZURE_DEPOLYMENT_ID}"
# api_key = "AZURE API KEY"
# max_tokens = 8096
# temperature = 0.0
# api_version="AZURE API VERSION" #"2024-08-01-preview"
# Optional configuration for specific LLM models
#[llm.vision]
#model = "claude-3-5-sonnet"
#base_url = "https://api.openai.com/v1"
#api_key = "sk-..."
결과적으로 나는 위와 같은 config 파일을 만들어서 저장해보았다.
하지만 안돼죠....
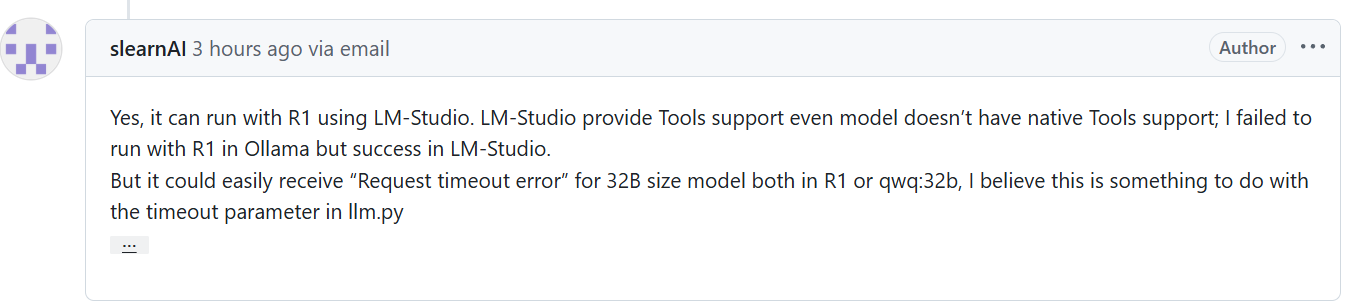
그러다 이 글을 봤다.
ollama말고 LM 스튜디오로 해보란다...
해보자...
LM스튜디오를 받고, 모델을 로드하고, 서버를 켜기만 하면 성공이다.
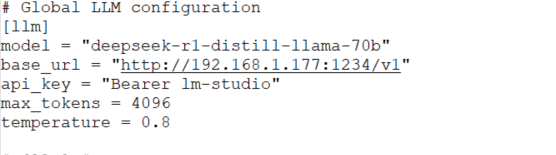
옵션은 이렇게 해보았다.

그랬더니 뭔가 되긴 한다.
manus가 내부적으로 툴을 고르고, 뭔가 하는 형태로 디자인 된 것 같다. 다른 문구를 넣어봐야겠다..
간단한 배치파일을 하나 만들어달라고 해봤다.
그런데 80b 모델로 돌리니까 너무 느리다. 한번 도는데 5분은 걸리는 느낌?

그랬더니 이렇게 타임 아웃이라는 결과가 나왔다.
헐.. 그리고 80b를 돌리고 있던 서버가 뻗었다....
일단 기능 검증용으로 8b 모델을 이용해봐야겠다... 성능 비교는 나중에 다시 하기로..

오? 뭔가 구글링도 하고, 검색도 하는 모양이다.... 그럴싸 한데?....
좀 더 여러가지 작업을 해보고, 이걸로 뭘 할 수 있는지 고민을 좀 해봐야겠다.
결과적으로 PC에 있는 툴들을 AI가 자동으로 실행해서 결과를 뽑아준다는 것이 차이점이다.
명령어를 잘 줄 수록 좋은 결과를 가져다 줄 것 같다.
명령어를 잘 준다는 의미는, 명확한 툴에 대한 지시도 포함이 되지 않을까?
뭔가 유의미한 것을 얻기 위해, 32B로 모델을 바꾸어서, 테스트해본다.
요구사항
can you draw a picture of cat and save it to cat.bmp on my desktop?
실행해본다.
GPU 온도가 80도 까지 올라가고 , GPU 사용률은 95%를 왔다갔다한다. 메모리는 21.6GB만 소비된 상태
헐?..

고양이 스러운 그림을 정말로 그려서, 바탕화면에 cat.bmp로 저장해놨다....
.

놀랍구만......LLM 모델 외에 Drawing 모듈 까지 넣을 수 있으면 좋을듯하다....신기하네..
'인공지능 공부' 카테고리의 다른 글
| OLLAMA로 로컬 API 서버 돌려보기 (0) | 2025.03.13 |
|---|---|
| Manus AI Agent 개념잡기 (0) | 2025.03.12 |
| miniconda 상에서 yolov10 이용해보기 (0) | 2025.01.13 |
| pytorch GPU 지원 설치하기 (0) | 2025.01.13 |
| CUDNN 설치하기 feat 환경변수, PATH (0) | 2025.01.13 |



