https://angeloyeo.github.io/2020/02/12/standard_error.html
표본과 표준 오차의 의미 - 공돌이의 수학정리노트
angeloyeo.github.io
위 링크를 통해서 배운 내용을 정리해본다.
1. 모집단(population): 관심 대상의 전체 집합
- 모수(parameter): 관심 대상 전체 집합의 특성 ex) 평균, 분산, 표준편차, 분위수, 모비율 등
2. 표본집단(sample): 랜덤하게 뽑은 표본들의 집합
- 표본통계랑(sample statistics): 표분 집합의 특성 ex) 표본 평균, 표본 표준편차, 표본 비율
- 표준오차(standard error of the mean, SEM): 표본 통계량의 표준 편차
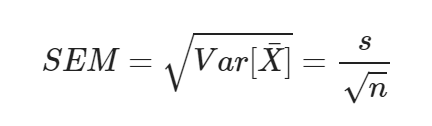
모집단과 표본집단은 위와 같이 정리.
다음으로 t-value를 보자.
https://angeloyeo.github.io/2020/02/13/Students_t_test.html
t-value의 의미와 스튜던트의 T 테스트 - 공돌이의 수학정리노트
angeloyeo.github.io
검정통계라는 개념이 들어간다.
1. 검정통계량: 통계적 가설의 진위 여부를 검정하기 위해 표본으로 부터 계산하는 통계량, 표본 통계량을 2차 가공한 것.
- 통계적 가설 진위 여부를 검정한다 = 검정통계량의 값이 기준이 벗어나지 확인하여 세워둔 가설이 틀렸다고 할 수 있는지 확인한다.
2. 두 표본 집단의 유의미한 차이가 있는지를 검정하는 과정
- 두 표본집단의 평균 만으로 결과를 뽑는건 내재한 오차(표본 평균이 가지는 표준 오차)를 반영하지 않기 때문에 적합하지 않음
- 음 이 뒤 내용은 너무 어렵다.
https://www.youtube.com/watch?v=mQXj456SWco
영상을 보고오자.
'인공지능 공부' 카테고리의 다른 글
| Populating 3D Scenes by Learning Human-Scene Interaction 둘러보기 (0) | 2023.02.03 |
|---|---|
| Primitive Object Grasping for Finger Motion Synthesis 둘러보기 (0) | 2023.01.20 |
| Running DynaBOA Step by step (0) | 2022.10.12 |
| Running DynaBOA Step by step (0) | 2022.09.27 |
| Language-Driven Synthesis of 3D Scenes from Scene Databases 읽어보기 (1) | 2022.09.25 |

